Thread pool efficiency
June 2015Introduction
In order to use a modern CPU to its full potential it is necessary to write multithreaded code. Fortunately, many problems can be split into units of work that have few or no interdependencies. These simple problems can often be written as a parallel for loop and the code base I am currently working on uses parallel for in dozens of places. Several libraries have been developed to simplify parallel programming and make this sort of parallelism trivial to add. For example, I can make the serial loop
parallel with minimal changes by using OpenMP
or the C++11 style Microsoft Parallel Patterns Library (PPL).
I wanted to investigate the impact that different threading libraries and scheduling policies have on performance. I was originally intending to test if I could make specific tasks run more quickly by giving them elevated priority relative to background tasks that would fill the remaining CPU cycles. My tests were giving me curiously inconsistent performance and low CPU utilization, so I eventually simplified the problem as much as I could.
I created a trivial test case that is completely data parallel, has uniform job sizes, and is entirely ALU limited. Because the amount computation is directly proportional to the number of work items, even the simplest scheduling policy should be effective. Namely, if there are $n$ items to process and $p$ processors, assign each processor a contiguous range of $n/p$ items.
Early to bed and early to rise makes a thread healthy, wealthy, and wise
I do not know exactly how the threading libraries I tested work internally, so I wrote a simple thread pool using standard threading primitives. My computer has a Xeon with 8 physical (16 logical) cores, so I create a pool of 16 worker threads. The workload I give is large enough to run for a bit over half a second, which should be more than sufficient to amortize scheduling overhead.
Having the threads block until they are all signaled to start had a ridiculously long latency regardless of if I used std::condition_variable, its native Win32 counterpart ConditionVariable, or a Win32 Semaphore to send the signal to start. The CPU utilization graph of each core shows that it takes about 300 ms for all of the threads to finally receive the signal. This is unfathomably slow compared to the tens of microseconds I expect, which is already quite slow because it requires kernel transitions.
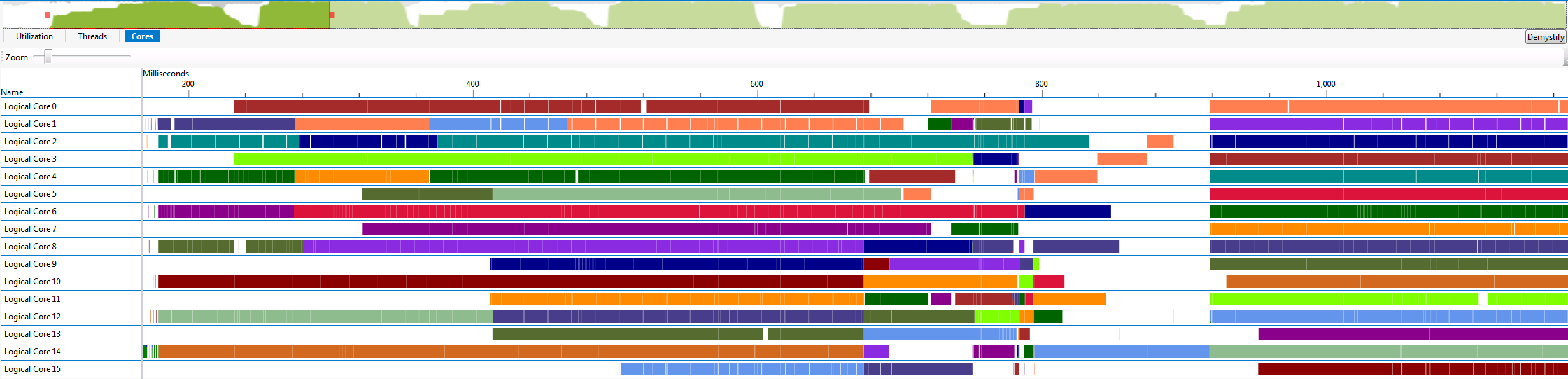
After staring at enough graphs and fiddling with enough options, I noticed that at least eight of the threads will always wake up immediately, with the remaining threads showing up with varying degrees of tardiness. When I remarked that the delay seemed to be tied to the number of physical cores to my co-worker Michal Iwanicki, he suggested that I set the CPU affinity mask for the threads. Restricting each thread to a single core completely fixed the mysterious latency I was seeing as shown in the graph below.
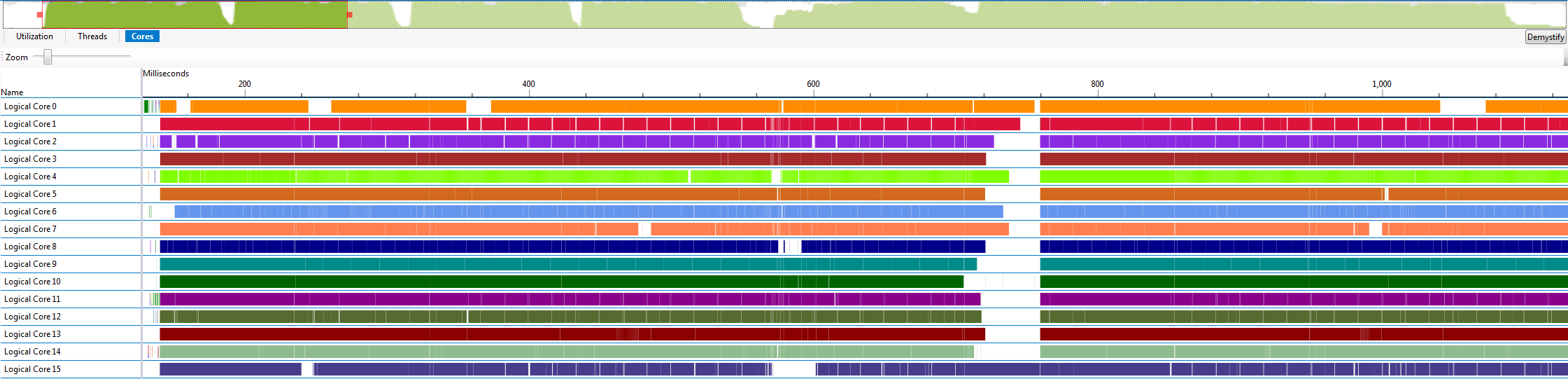
These results indicate that the threads are waking up late because the Windows kernel is horribly confused by hyper threads. Restricting threads to single logical cores is usually frowned upon, so I also tried a somewhat less restrictive approach of restricting pairs of threads to physical cores, but that gave the Windows freedom to introduce latency again. I have not tested performance on Windows 8, so there is a chance that Microsoft has already fixed this problem.
Comparing different libraries
Armed with this knowledge, it is interesting to compare the performance characteristics of different libraries and try to infer how they work. In the graphs below, each thread is one horizontal line. The color scheme is that green means busy, and blocked threads are colored according to why they are blocked: yellow means it was preempted, blue means it is sleeping, and red is the default blocked color. The traces I show are from sleeping for 100ms, running a sequence of four parallel for loops, sleeping for 50ms, then terminating.
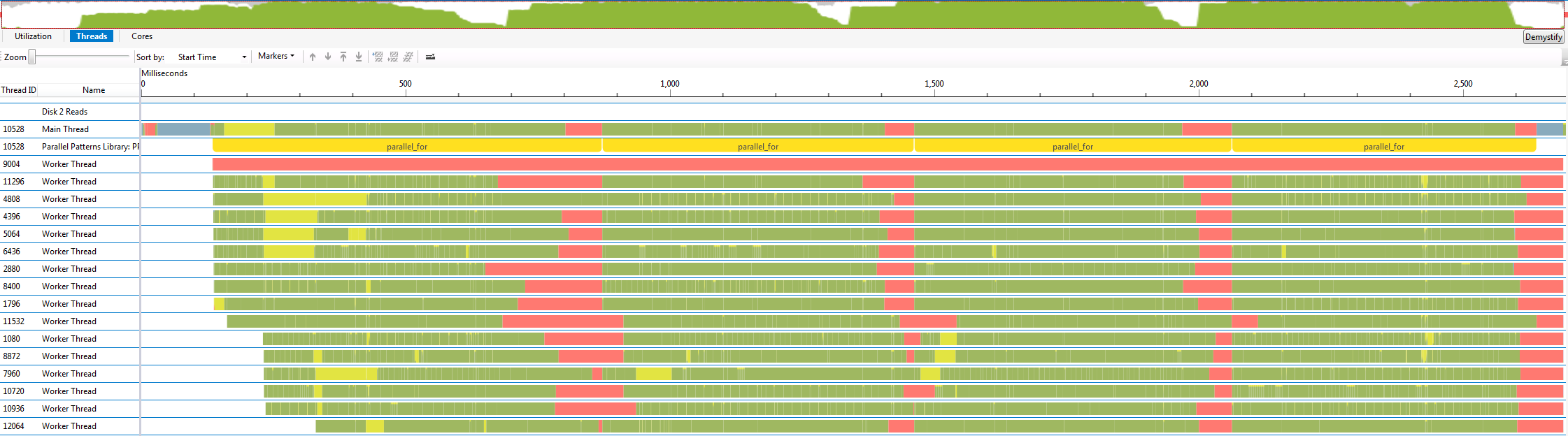
Microsoft's PPL clearly suffers from the latency issues I had. Threads are created for the pool when the first parallel loop is started. Some threads take a long time to create, which is probably the fault of the operating system. There is also a large amount of preemption in the first loop, which is somewhat surprising. Maybe the kernel is shuffling threads between cores while it tries to figure out the complicated problem of mapping 16 active threads to 16 cores.
I tried setting the thread affinity in PPL, but didn't have any success. Trying to set the affinity within a thread using GetCurrentThread then SetThreadAffinityMask failed, so I guessed that only the parent of a thread can set the affinity. It turns out that the handle returned by GetCurrentThread is only valid within the thread, but you can call DuplicateHandle to make a valid handle outside of the thread. Again, no luck. Another strange behavior I noticed is that PPL launched a 17th thread during the real workload after setting thread affinity, which should not be possible according the the documented default max concurrency.

The results from OpenMP confuse me. Threads seem to start quickly, which is promising. One possibility is that OpenMP manages not to confuse Windows because OpenMP creates exactly one thread per core, unlike PPL and my solution. However, there is a lot of preemption at the beginning.
What is really weird is that some of the threads try to start and immediately go back to sleep, which mirrors my own morning routine. The scheduler also seems to change how it works after the first parallel for. The first time threads block after finishing, but subsequent times the threads go into a busy wait. This makes it difficult to tell how long the threads are actually working rather than waiting and would require me to add instrumentation. In a different trace I determined that OpenMP will do a busy wait for 100ms before blocking again. Looking into it some more shows that the wait policy can be set to either spin or not using OMP_WAIT_POLICY, but Microsoft does not seem to allow control of the spin time. The implication of busy waiting is that subsequent tasks will start more quickly but that mixing OpenMP with other thread managers like PPL could be inefficient.
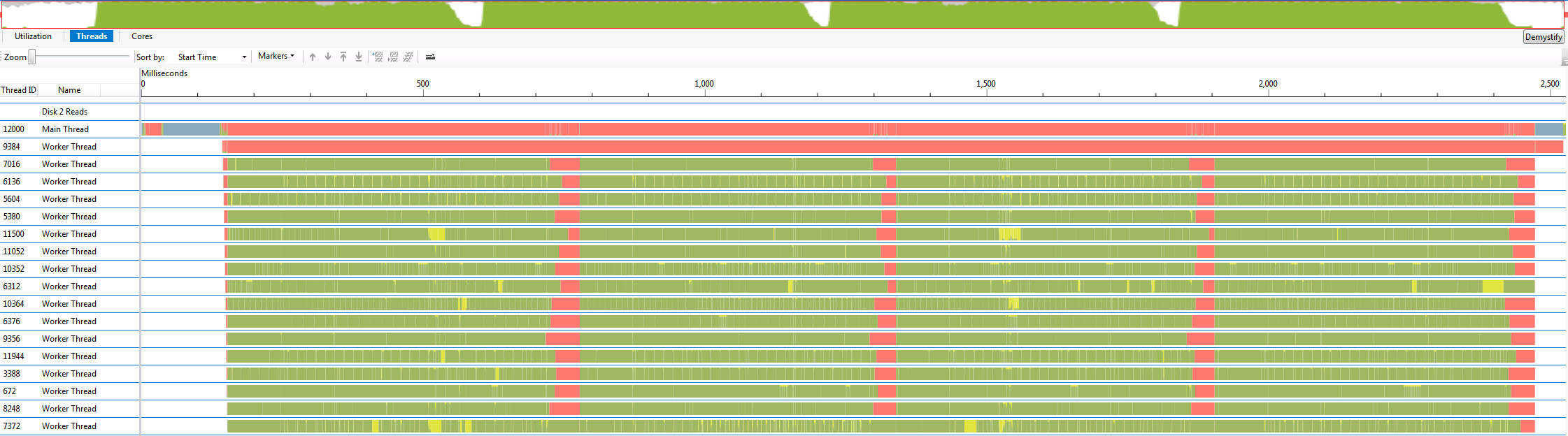
Lastly, I show the graph for my simple pool that restricts each thread to a logical core. After each job, I block until the next job. The results are exactly what one would expect, with no mysterious inefficiencies. Creating the threads takes 5ms (300us per thread) and all of the threads wake up from a signal within about 100us.